Replacing and Updating Html files using BeautifulSoup

Obey the principles without being bound by them.
, Bruce Lee
12 Jan 2019
Introduction
It is the new year again. For websites that consists mainly of static html pages that are built manually, a common task is to update the year and copyright information or some other common text/elements. This can be time consuming if the website has many pages. This article shows to automate such changes and modifications using BeautifulSoup, a python library for parsing html. It also shows how to use BeautifulSoup and Response to check for broken links in html files.
Not all static sites are built and maintained by hand. There are static site generators with templating system that allow changes to be made easily. However, for those who like to handcraft their own static html pages, BeautifulSoup can help to modify and update html files automatically and quickly. BeautifulSoup can also be used with Response to check for broken links in html files.
Design and Approach
My website has a customized design, meant to be minimal and simple. It consists mainly of static html pages with some dynamic components such as php based contact form, an application log in for a special function. The static pages are formatted consistently with a single footer that contains copyright, disclaimer and privacy statement. Apart from the contact form and the login function which requires the use of cookies due to their functionalities, the static pages are all cookie free.
It is relatively easy to parse each html page, locate the footer tag and update the copyright year from 2018 to 2019. A python 3 script using BeautifulSoup can be written to automate this task, going through a directory containing the html files recusrively and updating each one.
Another common element that I will want to update is the html link tag, <a> that opens up a link in a new window (target="_blank" attribute is set). An additional attribute rel="noopener noreferrer" can be added. This setting prevents scripts in the target window from trying to manipulate window.location and directing back to my original site for phishing attacks. It can also prevent leakages of location information. Note, setting "noreferrer" will prevent http referrer header from being sent to the target website.
For my current website, even without the rel setting, it is still secure and safe since it is mainly serving pages that are meant to be public. There are mechanisms to guard against phishing attack on the dynamic login page. However, adding the "noopener" and "noreferrer" settings will enhance privacy and security.
Many of my web pages has links to external websites, some of these links can become invalid after some time. BeautifulSoup can be used together with Response (a python library for HTTP) to automatically check for all the external links and flag out those that are invalid. Invalid in this case means the links are no longer reachable, giving a HTTP status code other than HTTP 200 OK or the link is redirected. Redirection does not necessarily indicate a broken link, but it can mean that there are some changes. The result of the check can be written to a file and a manual verification be done.
Implementation
The latest version of BeautifulSoup module can be installed using the pip3 command on my ubuntu 16 machine. To install simply run
BeautifulSoup supports a number of different parsers, including the built in python html parser. In this case, we will use the Lxml parser for performance reason. The Lxml parser can be installed using the following command.
The following shows the python 3 script, html_footer_replace.py, for updating the year in the html footer. It defines three main variables at the top of the script, the text to match (2018), the replacement text, and the directory containing the html files for my website. Note, it is important to backup your existing files before attempting to modify them.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 | #!/usr/bin/python3
# The MIT License (MIT)
#
# Copyright (c) 2019 Ng Chiang Lin
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
#
# Simple python3 script to replace year string
# in footer tag on static html pages in a
# directory recursively.
# The script doesn't follow symlinks.
# It uses BeautifulSoup 4 library with the lxml parser.
# The html files are assumed to be utf-8 encoded and well formed.
#
# Warning: The script replaces/modifies existing files.
# To prevent data corruption of data loss.
# Always backup your files first !
#
#
# Ng Chiang Lin
# Jan 2019
#
import os
from bs4 import BeautifulSoup
# Text to match
matchtext = "2018"
# Text to replace
replacetext = "© 2019 Ng Chiang Lin, 强林"
# Directory containing the html files
homepagedir = "HomePage"
def processDir(dir):
print("Processing ", dir)
dirlist = os.listdir(path=dir)
for f in dirlist:
f = dir + os.sep + f
if (os.path.isfile(f) and
(f.endswith(".html") or f.endswith(".htm")) and not
os.path.islink(f)) :
print("file: " , f)
updateFile(f)
elif os.path.isdir(f) and not os.path.islink(f):
print("Directory: ", f)
processDir(f)
def updateFile(infile):
try:
try:
fp = open(infile,mode='r', encoding='utf-8')
soup = BeautifulSoup(fp, "lxml", from_encoding="utf-8")
footer = soup.footer
if footer is not None:
for child in footer:
if matchtext in child:
child.replace_with(replacetext)
output = soup.encode(formatter="html5")
#quick hack to replace async="" with async
#in javascript tag
#for my use case this works but for complicated
#html may require other solutions
output = output.decode("utf-8")
output = output.replace('async=""','async')
writeOutput(infile, output)
os.replace(infile + ".new", infile)
finally:
fp.close()
except:
print("Warning: Exception occurred: ", infile)
def writeOutput(infile, output):
tempname = infile + ".new"
try:
try:
of = open(tempname, mode='w', encoding='utf-8')
#of.write(output.decode("utf-8"))
of.write(output)
finally:
of.close()
except:
print("Warning: Exception occurred: ", infile)
if __name__ == "__main__" :
processDir(homepagedir)
|
The python 3 source file is saved in utf-8 encoding as the source file contains utf-8 characters. The © in the replacement text as well as my chinese name are in utf-8. BeautifulSoup will convert the utf-8 © into © when it outputs the html.
The processDir() method is a recursive function that takes a single parameter, the path of the directory to process. It starts off with the top directory path that contains the html files. When it encounters a subdirectory, it calls itself again with the subdirectory path as its parameter, recursively processing the subdirectory. It does this until all the files and subdirectories have been processed. The following shows the processDir() method.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | def processDir(dir):
print("Processing ", dir)
dirlist = os.listdir(path=dir)
for f in dirlist:
f = dir + os.sep + f
if (os.path.isfile(f) and
(f.endswith(".html") or f.endswith(".htm")) and not
os.path.islink(f)) :
print("file: " , f)
updateFile(f)
elif os.path.isdir(f) and not os.path.islink(f):
print("Directory: ", f)
processDir(f)
|
Notice that it checks that the file or directory is not a symbolic link before processing it. For directory this is an important check that can prevent infinite loop. For example, a directory can be wrongly symbolicly linked to itself or linked in a circular manner. Files that ends with ".html" or ".htm" will be parsed and processed. The updateFile() method is called to modify each html file.
The following shows the code snippet of the updateFile() method. It takes a single parameter, the path of the html file to be updated.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | def updateFile(infile):
try:
try:
fp = open(infile,mode='r', encoding='utf-8')
soup = BeautifulSoup(fp, "lxml", from_encoding="utf-8")
footer = soup.footer
if footer is not None:
for child in footer:
if matchtext in child:
child.replace_with(replacetext)
output = soup.encode(formatter="html5")
#quick hack to replace async="" with async
#in javascript tag
#for my use case this works but for complicated
#html may require other solutions
output = output.decode("utf-8")
output = output.replace('async=""','async')
writeOutput(infile, output)
os.replace(infile + ".new", infile)
finally:
fp.close()
except:
print("Warning: Exception occurred: ", infile)
|
It opens the file using the utf-8 encoding (all my web files are utf-8 encoded) in read-only mode. It then initializes a BeautifulSoup object with the opened file object, specifying utf-8 encoding and lxml as the parser. It obtains the footer tag and loops through all its children looking for the matching string "2018". When the string containing "2018" is found, it is replaced with the new year and copyright information.
To prevent BeautifulSoup from adding a "/" to tags that doesn't come with a corresponding closing tag, such as <br> becoming <br/>, the html5 formatter is specified. This is done when encoding the output. The html5 formatter also prevents BeautifulSoup from converting > entity into > in its output.
BeautifulSoup seems to convert the async attribute in a javascript tag into async="". A quick way to resolve this is to convert the output into a utf-8 string and then do string replacement. Replacing async="" back to async. This works for my web pages as there are no other specific usages of async. For other more complicated content or html, a mass string replacement solution may not work.
output = output.replace('async=""','async')
The modified output is then written to a new temporary file through the writeOutput() method. The original html file is replaced by the newly created temporary file through the os.replace() method. Care is taken to ensure that the original html file object is closed through the use of try and finally block. When updating thousands or large number of html files, resources such as file descriptors have to be freed properly to prevent resource leakage. Any exceptions are caught in a try except block and a warning is printed out.
The following shows the writeOutput() method. It takes 2 parameters, the path of the original html file and the new modified output.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | def writeOutput(infile, output):
tempname = infile + ".new"
try:
try:
of = open(tempname, mode='w', encoding='utf-8')
#of.write(output.decode("utf-8"))
of.write(output)
finally:
of.close()
except:
print("Warning: Exception occurred: ", infile)
|
A temporary file name is created by combining the original file path with a ".new" extension. The modified output is then written to this file. Again care is taken to properly close the file object.
The main method (__main__) of the script is the entry point when the script is executed. It starts the processing by calling processDir(homepagedir).
1 2 | if __name__ == "__main__" :
processDir(homepagedir)
|
The script can be executed using the following command.
Modifying links that open a new window
Besides the script to change the year in the footer, we will create another script that will modify all <a> tags with the target="_blank" attribute. The script will add a rel="noopener noreferrer" attribute to the tag.
The following shows the python 3 script, html_ahref_replace.py.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 | #!/usr/bin/python3
# The MIT License (MIT)
#
# Copyright (c) 2019 Ng Chiang Lin
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
#
#
# Simple python3 script to
# add rel="noopener noreferrer" attribute to link <a> tag
# that opens the target in a new window (target="_blank")
# This is to protect against security vulnerability that can
# cause phishing or private information leakage.
#
# The script modifies all html files in a directory recursively.
# The script doesn't follow symlinks.
# It uses BeautifulSoup 4 library with the lxml parser.
# The html files are assumed to be utf-8 encoded and well formed.
#
# Warning: The script replaces/modifies existing files.
# To prevent data corruption of data loss.
# Always backup your files first !
#
#
# Ng Chiang Lin
# Jan 2019
#
import os
from bs4 import BeautifulSoup
# Text to match
matchtext = "_blank"
# Attribute and its content to be added
relattr = {'rel':'noopener noreferrer'}
# Directory containing the html files
homepagedir = "HomePage"
def processDir(dir):
print("Processing ", dir)
dirlist = os.listdir(path=dir)
for f in dirlist:
f = dir + os.sep + f
if (os.path.isfile(f) and
(f.endswith(".html") or f.endswith(".htm")) and not
os.path.islink(f)) :
print("file: " , f)
updateFile(f)
elif os.path.isdir(f) and not os.path.islink(f):
print("Directory: ", f)
processDir(f)
def updateFile(infile):
try:
try:
fp = open(infile,mode='r', encoding='utf-8')
soup = BeautifulSoup(fp, "lxml", from_encoding="utf-8")
alist = soup.find_all('a')
for ahref in alist:
if ahref.has_attr('target'):
if matchtext in ahref['target']:
appendAttr(ahref)
output = soup.encode(formatter="html5")
#quick hack to replace async="" with async
#in javascript tag
#for my use case this works but for complicated
#html may require other solutions
output = output.decode("utf-8")
output = output.replace('async=""','async')
writeOutput(infile, output)
os.replace(infile + ".new", infile)
finally:
fp.close()
except:
print("Warning: Exception occurred: ", infile)
def appendAttr(ahref):
for key, val in relattr.items():
if ahref.has_attr(key):
# Handle the case where rel attribute already present
# and contains "license" as value
# Any other value will be overwritten
oldval = ahref[key]
if "license" in oldval:
ahref[key] = "license " + val
else:
ahref[key] = val
else:
ahref[key] = val
def writeOutput(infile, output):
tempname = infile + ".new"
try:
try:
of = open(tempname, mode='w', encoding='utf-8')
of.write(output)
finally:
of.close()
except:
print("Warning: Exception occurred: ", infile)
if __name__ == "__main__" :
processDir(homepagedir)
|
It is structured similarly to the earlier footer replacement script. Some of the differences is that it uses the find_all() method from BeautifulSoup to obtain a list of all the <a> tags. If a tag contains a target attribute set to "_blank", it will be processed further. The rel="noopener noreferrer" attribute will be added. If a rel attribute already exists and contains a value of "license", the "noopener noreferrer" will be appended. Any other types of rel value will be overwritten by "noopener noreferrer".
The output is then written to a temp file which will then replace the original html file. Again resources such as file objects are closed properly.
Checking for Broken Links Using BeautifulSoup and Requests
To check for broken links in html files, we will require another python module, Requests. Requests is a HTTP library that makes it easy to make HTTP and HTTPS connections. Use the following command to install Requests using pip3.
The python 3 script for checking broken links is shown below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 | #!/usr/bin/python3
# The MIT License (MIT)
#
# Copyright (c) 2019 Ng Chiang Lin
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
# Simple python3 script to check for broken links in a directory of html files
# It uses BeautifulSoup and Response and recursively check
# html files in a directory.
# The script only checks for absolute links (starting with http) and can be configured
# to ignore your own domain. i.e. checking only absolute links to external
# websites. The script considers http redirection as well as a non HTTP 200 status
# as indicating that a link is broken. It spawns a number of threads to speed up
# the network check.
# The results are written to a file brokenlinks.txt. Existing file with the same name
# will be overwritten.
#
#
#
# Ng Chiang Lin
# Jan 2019
import os
import requests
from bs4 import BeautifulSoup
from queue import Queue
from threading import Thread
# domain to exclude from checks
exclude = "nighthour.sg"
# Directory containing the html files
homepagedir = "HomePage"
# A list holding all the html doc objects
htmldocs = []
# Number of threads to use for checking links
numthread = 10
# User-Agent header string
useragent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0"
# The results file
outputfile = "brokenlinks.txt"
class Link:
"""
This class represents a link <a href=".."> in a html file
It has the following variables
url: the url of the link
broken: a boolean indicating whether the link is broken
number: the number of occurences in the html file
"""
def __init__(self, url):
self.url = url
self.broken = False
self.number = 1
class HTMLDoc:
"""
This class represents a html file
It has the following member variables.
name: filename of the html file
path: file path of the html file
broken_link: A boolean flag indicating whether the
html file contains broken links
links: A dictionary holding the links in the html file.
It uses the url string of the link as the key.
The value is a Link object.
"""
def __init__(self, name, path):
self.name = name
self.path = path
self.broken_link = False
self.links = {}
def addLink(self, url, link):
ret = self.links.get(url)
if ret :
ret.number = ret.number + 1
self.links[url] = ret
else:
self.links[url] = link
def hasBroken(self):
return self.broken_link
def setBroken(self):
self.broken_link = True
def processDir(dir):
print("Processing ", dir)
dirlist = os.listdir(path=dir)
for f in dirlist:
filename = f
f = dir + os.sep + f
if (os.path.isfile(f) and
(f.endswith(".html") or f.endswith(".htm")) and not
os.path.islink(f)) :
print("file: " , f)
processHTMLDoc(filename, f)
elif os.path.isdir(f) and not os.path.islink(f):
print("Directory: ", f)
processDir(f)
def processHTMLDoc(filename, path):
try:
try:
fp = open(path,mode='r', encoding='utf-8')
soup = BeautifulSoup(fp, "lxml", from_encoding="utf-8")
alist = soup.find_all('a')
htmlobj = HTMLDoc(filename, path)
for link in alist:
processDocLink(link, htmlobj)
htmldocs.append(htmlobj)
finally:
fp.close()
except:
print("Warning: Exception occurred: ", path)
def processDocLink(link, htmlobj):
if(link.has_attr('href')):
location = link['href']
if (location.startswith("http") and
exclude not in location) :
linkobj = Link(location)
htmlobj.addLink(location, linkobj)
def checkBrokenLink(htmlqueue, tnum):
while True:
htmlobj = htmlqueue.get()
print("Thread ", tnum, " processing ", htmlobj.name)
links = htmlobj.links
try:
for k, v in links.items():
linkobj = v
try:
headers = {'User-Agent':useragent}
r = requests.get(linkobj.url, headers=headers, allow_redirects=False)
if r.status_code != 200:
print("Broken link : ", htmlobj.path ,
" : " , linkobj.url)
linkobj.broken = True
htmlobj.broken_link = True
except:
print("Broken link : ", htmlobj.path ,
" : " , linkobj.url)
linkobj.broken = True
htmlobj.broken_link = True
finally:
htmlqueue.task_done()
def writeResults():
with open(outputfile, mode='w', encoding='utf-8') as fp:
fp.write("==================== Results =============================\n")
fp.write("Html File Path ; Broken Link ; Number of links in file\n")
fp.write("==========================================================\n\n")
for html in htmldocs:
if html.hasBroken():
for k, v in html.links.items():
link = v
if link.broken:
output = html.path + " ; " + link.url + " ; " + str(link.number) + "\n"
fp.write(output)
fp.close()
if __name__ == "__main__" :
processDir(homepagedir)
htmlqueue = Queue()
for i in range(numthread):
worker = Thread(target=checkBrokenLink,args=(htmlqueue,i,))
worker.setDaemon(True)
worker.start()
for html in htmldocs:
htmlqueue.put(html)
htmlqueue.join()
print("\n\n\n")
print("Checking done, writing results to ", outputfile)
writeResults()
print("Completed. Check the results in ", outputfile)
|
A much more object oriented approach is taken. Two classes are defined. Link and HTMLDoc. Link represents a link in a html file. It has a url, a number indicating the number of occurences in the html document and a boolean flag. The boolean flag is used to indicate whether the link is broken and invalid.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | class Link:
"""
This class represents a link <a href=".."> in a html file
It has the following variables
url: the url of the link
broken: a boolean indicating whether the link is broken
number: the number of occurences in the html file
"""
def __init__(self, url):
self.url = url
self.broken = False
self.number = 1
|
The HTMLDoc class represents a single html file. It has a file name, a path, a boolean flag indicating whether the document contains broken links and a dictionary holding Link objects. The key of the dictionary is the url of the Link object.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | class HTMLDoc:
"""
This class represents a html file
It has the following member variables.
name: filename of the html file
path: file path of the html file
broken_link: A boolean flag indicating whether the
html file contains broken links
links: A dictionary holding the links in the html file.
It uses the url string of the link as the key.
The value is a Link object.
"""
def __init__(self, name, path):
self.name = name
self.path = path
self.broken_link = False
self.links = {}
def addLink(self, url, link):
ret = self.links.get(url)
if ret :
ret.number = ret.number + 1
self.links[url] = ret
else:
self.links[url] = link
def hasBroken(self):
return self.broken_link
def setBroken(self):
self.broken_link = True
|
The python 3 script first calls the processDir() method which recursively goes through a directory containing html files. It processes each html file that it encounters and store it in a HTMLDoc object. Each HTMLDoc object is added to a global python list, htmldocs. Once all the html files are stored as HTMLDoc objects in the list, the actual checking will start.
The script is single threaded when building the python list of HTMLDoc objects. To speed up network checking of the links in each HTMLDoc objects, additional threads are spawned. Network lookups are IO bound and using additional threads will improve performance of the script.
The following code snippet shows the __main__ method of the python 3 script.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | if __name__ == "__main__" :
processDir(homepagedir)
htmlqueue = Queue()
for i in range(numthread):
worker = Thread(target=checkBrokenLink,args=(htmlqueue,i,))
worker.setDaemon(True)
worker.start()
for html in htmldocs:
htmlqueue.put(html)
htmlqueue.join()
print("\n\n\n")
print("Checking done, writing results to ", outputfile)
writeResults()
print("Completed. Check the results in ", outputfile)
|
The standard technique of multithreading in python is to create a queue for storing the tasks to be processed. The script starts 10 worker threads, each thread pulling HTMLDoc objects from the queue for processing. All the threads are marked as daemon thread. This means that when the main program exits, all the threads will also be terminated. The HTMLDoc objects are then added as tasks to the queue. In the main program thread, the join() method is called on the queue so that it waits for all 10 threads to complete.
When each task is completed, a thread will mark the task as done in the queue. The main program resumes execution once all the tasks or HTMLDoc objects are processed. It then calls the writeResults() method to write the results into a text file brokenlinks.txt.
We can then manually verify the results in the file and update the links in the html files accordingly. The following shows the results file.
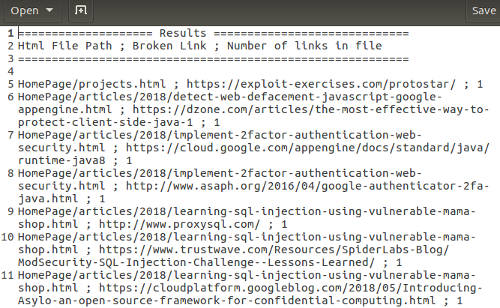
Each of the result line contains the following fields delimited by a semi-colon.
The source code for all the 3 scripts are available at the Github link below.
Conclusion and Afterthought
BeautifulSoup is a useful module that can be used for web scraping and even help to automate mass modification of static html files. Static html websites offer many advantages over CMS powered by an application framework and a database. It is simple, uses less computing resources, easier to cache and has a far smaller attack surface.
A website that consists of mainly static html files are ideal for a simple personal site. There are also static site generators with templating support that make it easy to build static websites. For more complicated uses, a flat file based CMS system can be used. Flat file CMS offers a simplified framework without relying on a database backend, this help to reduce the attack surface, resource usage and improves performance.
For handcrafted static pages, BeautifulSoup removes the time consuming process of mass updates/modifications of common elements in static files. It is easy to learn and can be scripted according to your needs. When used in combination with a module like Requests, it can be used to automate the checking of broken html links.
Useful References
- BeautifulSoup Website, The python module that can be used for parsing and processing html files.
- Python Requests: HTTP for Human, The python requests module that can be used to make HTTP and HTTPS connections.
- OWASP on Reverse Tabnabbing, An owasp article explaining about the vulnerability of having target="_blank" in links.
The full source code for the scripts are available at the following Github link.
https://github.com/ngchianglin/BeautifulSoupHTMLReplace
If you have any feedback, comments, corrections or suggestions to improve this article. You can reach me via the contact/feedback link at the bottom of the page.